
Google Keepで画像からテキストを抽出することができます。(以前の記事でも紹介済)
このGoogle Keepのテキスト抽出は複数の画像でも行えます。例えば、10枚の画像のテキスト抽出を1回の操作で行えるということです。
Google Keepとは
Googleが提供するメモアプリ及びウェブサービスです。Googleアカウントがあれば誰でも使えます。下記のURLでアクセス可能です。

Sign in - Google Accounts
keep.google.com
テキスト抽出手順(複数画像ファイル)
下記はPCでの手順です。スマホの場合は、各画像ファイルで「画像のテキストを抽出」メニューを実行する形となるため、複数画像ファイルのテキスト抽出はできません。
- PCのローカルフォルダに画像を用意する。
今回の例ではデスクトップにocrフォルダを作成し、そのフォルダの中に11枚の書籍の写真画像ファイルを置きました。
各ファイルに1~11の番号を採番しています。(便宜上採番しているだけなので必須ではありません)

- Google Keep(https://keep.google.com/)にアクセスし、複数の画像をテキストエリアの「メモを入力…」と表示されているところにドラッグします。複数画像を一度にまとめてドラッグすることもできますが、アップロード順が逆(例:1→11の順でアップロードしたつもりが11→1の順にアップロードしてしまったなど)の場合は、テキスト抽出した結果も逆になるので注意が必要です。今回の例でいうと、1→11のファイルを選択して、1のファイルをドラッグすると1→11の順でアップロードできました。

- 複数画像ファイルを1つのメモにドラッグすると以下のようになります。すべての画像が表示されてはいませんが、アップロードした画像はすべて1つのメモに格納されています。

- 「︙」から「画像のテキストを抽出」をクリックします。

- 下記のように、テキスト抽出ができます。
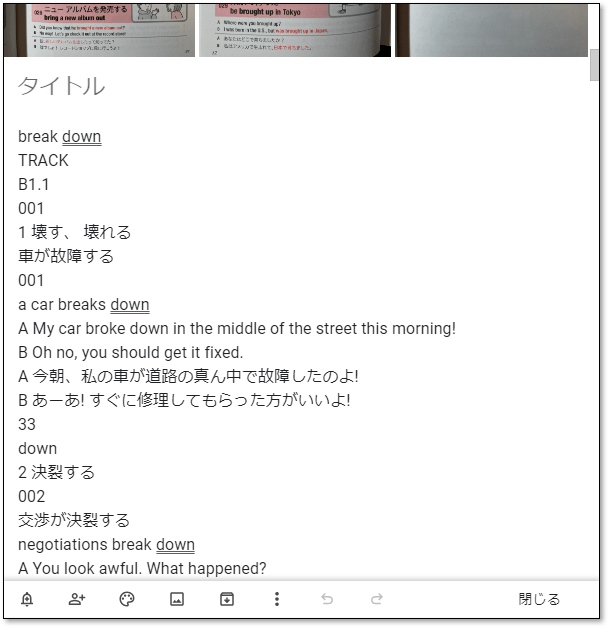

問題点
Google Keepを使ったテキスト抽出は簡単でOCRの精度も高いのでおすすめですが、下記の注意点があります。
- 画像ファイルのサイズが大きい場合、アップロードに時間がかかります。
- 画像ファイルの枚数が多い、ファイルサイズが大きいなどの場合、「画像のテキストを抽出」メニューが使用できるようになるまでに時間がかかります。
「画像のテキストを抽出」メニューが使用できるようになったからと言って、すべての画像ファイルのテキスト抽出ができるようになるわけではありません。つまり、「画像のテキストを抽出」メニューを実行しても一部の画像ファイルのテキスト抽出しかできず、すべての画像ファイルのテキスト抽出ができるまでに数分のタイムラグが生じます。参考までに、今回、私がアップロードした11枚の画像ファイル(各ファイルは4~5MB)でいうと、すべての画像ファイルのテキスト抽出ができるようになるまでに5分以上かかりました。けっこう遅いと思います。
どうやら、「画像のテキストを抽出」メニューを実行したときにOCRされるのではなくて、アップロードした段階でGoogle側でOCRしているようです。そのため、Google Keepを使用したテキスト抽出は
- 画像ファイルが少ない場合
- 画像のファイルサイズが小さい場合(スマホのスクショや圧縮したファイルなど)
- OCRのテキスト量が少ない場合
- あらかじめ画像ファイルをアップロードしておいて、後からまとめてテキスト抽出する場合
などに限定されそうです。書籍をまるごとOCRする場合などは不向きかもしれませんね。また、スマホでは1つの画像ファイルしかOCRできないのも不便ですね。